今日值得关注的大模型前沿论文
HyperAgent:解决大规模编码任务的通用软件工程智能体
有话直说:仅需提示的自奖励在线偏好优化
MaskLLM:大语言模型的可学习剪枝方法
一种无需训练的架构搜索框架:寻找高效大语言模型
基于多模态 Token 的基础模型:具备多对多理解生成能力
清华、北邮团队推出由大模型驱动的主动式助手 AssistantX
减少 1000 倍输入 Token,新方法加速长上下文 LLM
EMOVA:赋予语言模型看、听、说能力
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看“2024必读大模型论文”
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
HyperAgent:解决大规模编码任务的通用软件工程智能体
大语言模型(LLM)给软件工程(SE)带来了革命性的变化,在各种编码任务中展现了非凡的能力。虽然最近的努力已经产生了基于 LLM 的自主软件智能体,用于端到端开发任务,但这些系统通常是为特定的 SE 任务而设计的。
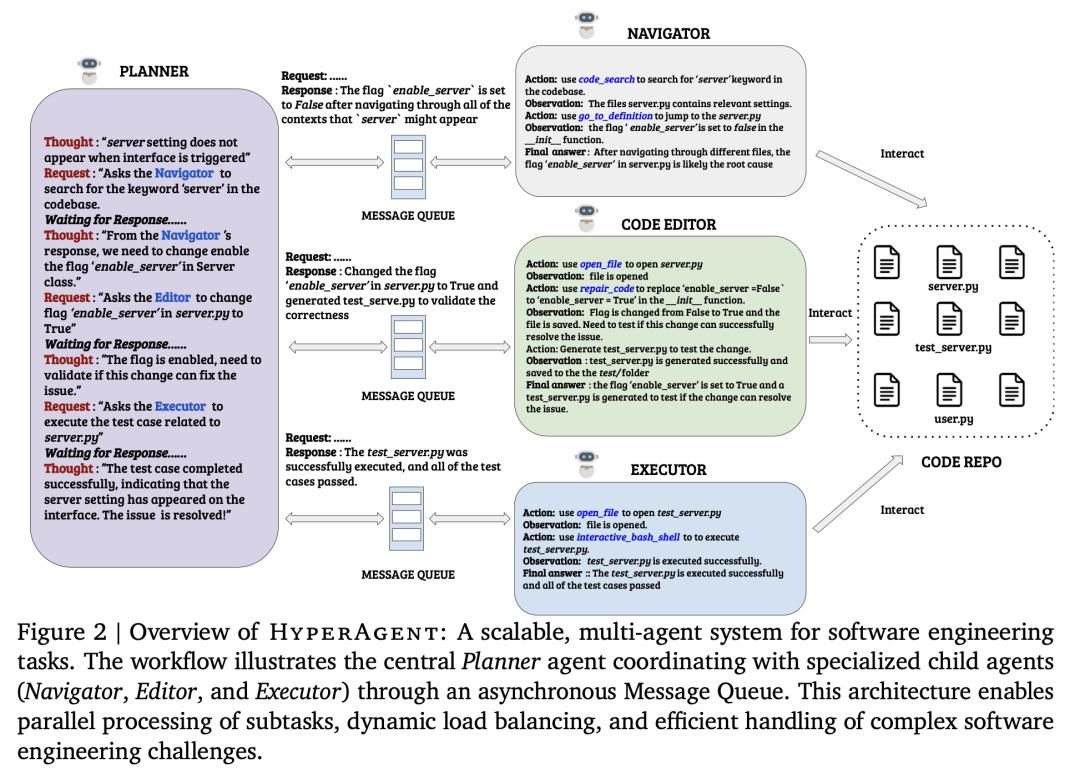
FPT Software 推出的 HyperAgent 是一种新型通用多智能体系统,旨在通过模仿人类开发人员的工作流程,解决不同编程语言的各种 SE 任务。该系统由四个专门智能体组成:Planner、Navigator、Code Editor 和 Executor。HyperAgent 可管理 SE 任务从最初构思到最终验证的整个生命周期。通过广泛评估,HyperAgent 在各种 SE 任务中实现了 SOTA 性能:在 GitHub 问题解决方面,HyperAgent 在 SWE-Bench-Lite 上的成功率为 25.01%,在 SWE-Bench-Verified 上的成功率为 31.40%,超过了现有方法。
此外,HyperAgent 还在版本库级代码生成(RepoExec)、故障定位和程序修复(Defects4J)方面展示了 SOTA 性能,其表现往往优于专业系统。
论文链接:
https://arxiv.org/abs/2409.16299
有话直说:仅需提示的自奖励在线偏好优化
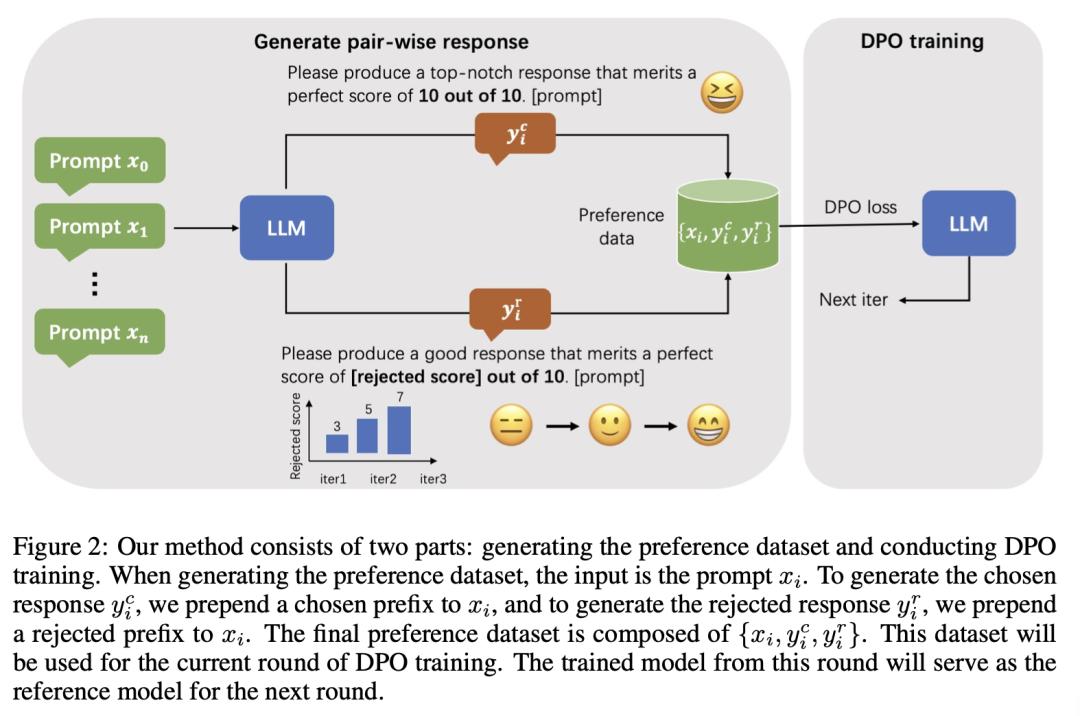
来自上海科技大学、西北大学和字节跳动的研究团队针对基于人类反馈的强化学习(RLHF)所面临的挑战,重点研究了自奖励对齐方法。在在线 RLHF 中,获取反馈需要与环境进行交互,而在使用额外奖励模型或 GPT-4 API 时,交互成本可能会很高。目前的自奖励方法在很大程度上依赖于判别器的判断能力,这对大型模型很有效,但要移植到小型模型上却很困难。
为了解决这些局限性,他们提出了一种新颖的、仅提示的自奖励在线算法,该算法无需依赖判断能力即可生成偏好数据集。此外,他们还对正面和负面示例之间的最佳差距进行了精细的算术控制,在训练的后期阶段生成更多的硬负示例,以帮助模型更好地捕捉人类微妙的偏好。最后,他们在两个基础模型 Mistral-7B 和 Mistral-Instruct-7B 上进行了广泛的实验,这两个模型大大提高了参考模型的性能,在 AlpacaEval 2.0 的长度控制胜率中达到了 34.5%。
论文链接:
https://arxiv.org/abs/2409.17534
MaskLLM:大语言模型的可学习剪枝方法
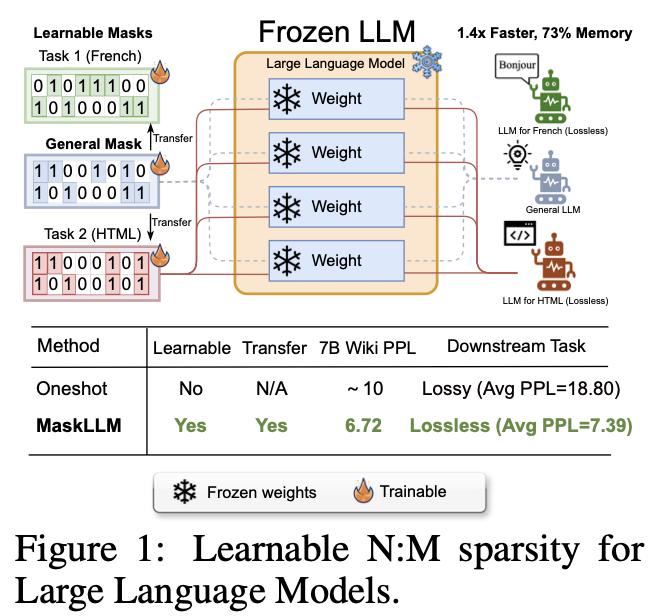
大语言模型(LLM)的显著特点是参数数量庞大,通常会产生大量冗余。来自新加坡国立大学和英伟达的研究团队提出了一种可学习剪枝方法——MaskLLM,它在 LLM 中建立了半结构化(或“N:M”)稀疏性,旨在减少推理过程中的计算开销。MaskLLM 没有开发新的重要性准则,而是通过 Gumbel Softmax 采样将 N:M 模式明确建模为可学习分布。
这种方法有利于在大规模数据集上进行端到端训练,并具有两个显著优势:1) 高质量掩码——他们的方法可有效扩展到大型数据集,并学习到准确的掩码;2) 可迁移性——掩码分布的概率建模可实现跨领域或跨任务的稀疏性迁移学习。
他们在各种 LLM(包括 LLaMA-2、Nemotron-4 和 GPT-3)上评估了使用 2:4 稀疏性的 MaskLLM,参数大小从 843B 到 15B 不等,实验结果证明,与 SOTA 方法相比,这种方法有了很大改进。例如,与密集模型的 5.12 PPL 相比,其他领先方法在维基文本上实现了 10 或更高的复杂度(PPL),但 MaskLLM 仅通过使用冻结权重学习掩码就实现了显著更低的 6.72 PPL。此外,MaskLLM 的可学习特性允许定制掩码,以便将 2:4 稀疏性无损地应用到下游任务或领域中。
论文链接:
https://arxiv.org/abs/2409.17481
GitHub 地址:
https://github.com/NVlabs/MaskLLM
一种无需训练的架构搜索框架:寻找高效大语言模型
大语言模型(LLM)在人工智能研究领域长期占据重要地位。许多高效的技术,包括权重剪枝、量化和提炼,都被用来压缩 LLM,目标是减少内存和加速推理,这凸显了 LLM 的冗余性。然而,大多数模型压缩技术都集中在权重优化上,忽略了对最佳架构的探索。此外,传统的架构搜索方法受限于大量参数带来的复杂性提升,难以在 LLM 上展示其有效性。
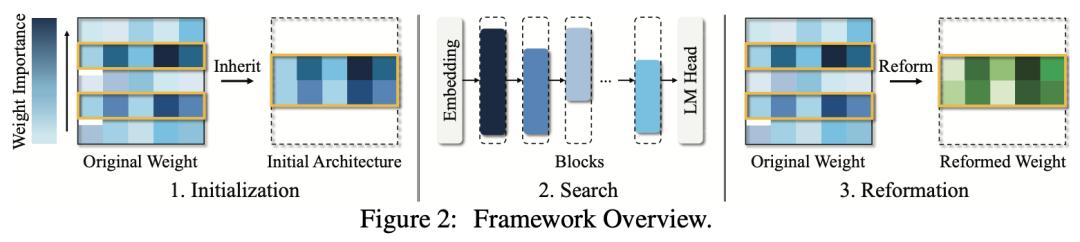
来自东南大学的研究团队及其合作者提出了一种无需训练的架构搜索框架,以识别最优子网,在实现推理加速的同时保留原始 LLM 的基本优势。此外,在生成继承了原始 LLM 特定权重的子网后,他们推出了一种新算法,利用省略的权重,通过少量校准数据来修正继承的权重。
与可以生成较小网络的 SOTA 免训练结构化剪枝工作相比,他们的方法在标准基准中表现出更优越的性能。此外,他们生成的子网可以直接减少 GPU 内存的使用,实现推理加速。
论文链接:
https://arxiv.org/abs/2409.17372
基于多模态 Token 的基础模型:具备多对多理解生成能力
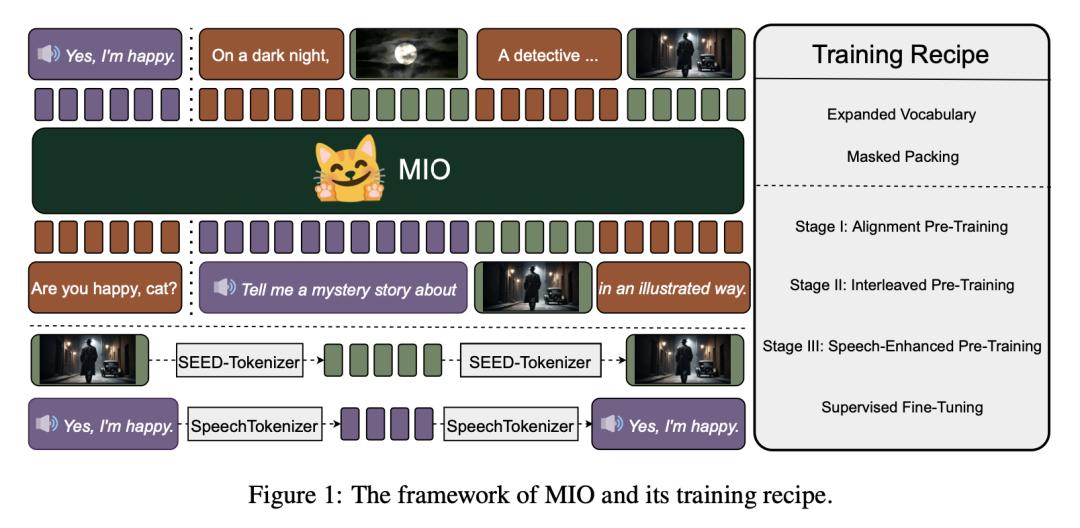
来自北京航空航天大学、零一万物和 M-A-P 的研究团队及其合作者,推出了一个基于多模态 Token 的新型基础模型——MIO,其能够以端到端的自回归方式理解和生成语音、文本、图像和视频。
虽然大语言模型(LLM)和多模态大语言模型(MM-LLM)的出现通过其多功能性推动了通用人工智能的发展,但它们仍然缺乏真正的多对多理解和生成能力。最近,GPT-4o 的发布展示了多对多 LLM 在复杂现实任务中的巨大潜力,实现了跨图像、语音和文本的全方位输入和输出。然而,它是闭源的,不支持生成多模态交错序列。
MIO 是通过因果多模态建模,在四种模态的离散 Token 混合物上进行训练的,经历了四个阶段的训练过程:(1)对齐预训练;(2)交错预训练;(3)语音增强预训练;(4)在各种文本、视觉和语音任务上进行全面的监督微调。
实验结果表明,与以前的双模态基线、多对多模型基线,甚至特定模态基线相比,MIO 的性能具有竞争力,在某些情况下甚至更胜一筹。此外,MIO 还展示了其多对多特性所固有的高级功能,如交错视频文本生成、视觉思维链推理、视觉指南生成、教学图像编辑等。
论文链接:
https://arxiv.org/abs/2409.17692
清华、北邮团队推出由大模型驱动的主动式助手
AssistantX
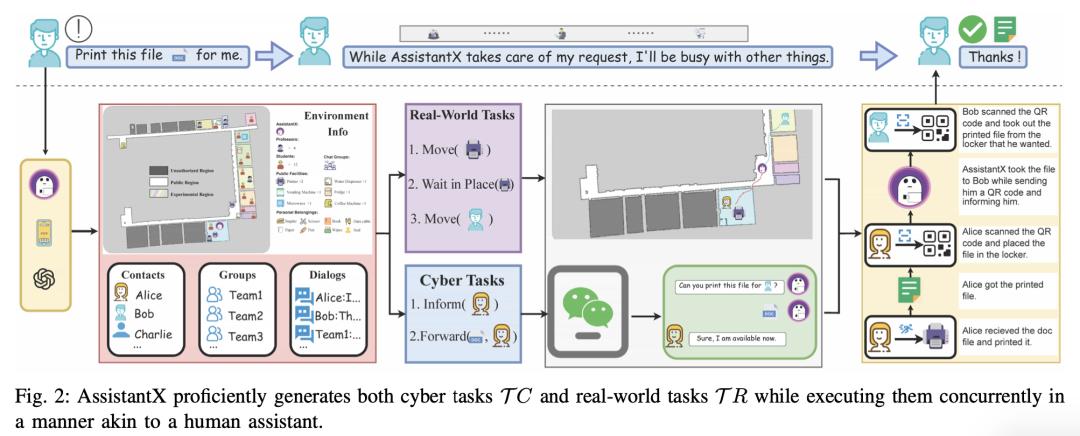
人机协作环境中对智能助理的需求日益增长,推动了对自主机器人系统的大量研究。然而,传统的服务机器人和虚拟助手由于动态推理和交互能力有限,在现实世界的任务执行中举步维艰,尤其是在需要人类协作的情况下。大语言模型的最新发展为改进这些系统开辟了新途径,使其具备更复杂的推理和自然交互能力。
来自清华大学和北京邮电大学的研究团队推出了一款由大语言模型驱动的主动式助手 AssistantX,它可以在物理办公环境中自主运行。与传统的服务机器人不同,AssistantX 利用新型多智能体架构 PPDR4X 提供先进的推理能力和全面的协作意识。通过有效弥合虚拟操作和物理交互之间的差距,AssistantX 在管理复杂的现实世界场景方面表现出了鲁棒性。
他们的评估凸显了该架构的有效性,表明 AssistantX 能够响应明确的指令,主动从内存中检索补充信息,并主动寻求团队成员的协作,以确保任务的顺利完成。
论文链接:
https://arxiv.org/abs/2409.17655
GitHub 地址:
https://assistantx-agent.github.io/AssistantX/
减少 1000 倍输入 Token,新方法为长上下文 LLM 提速
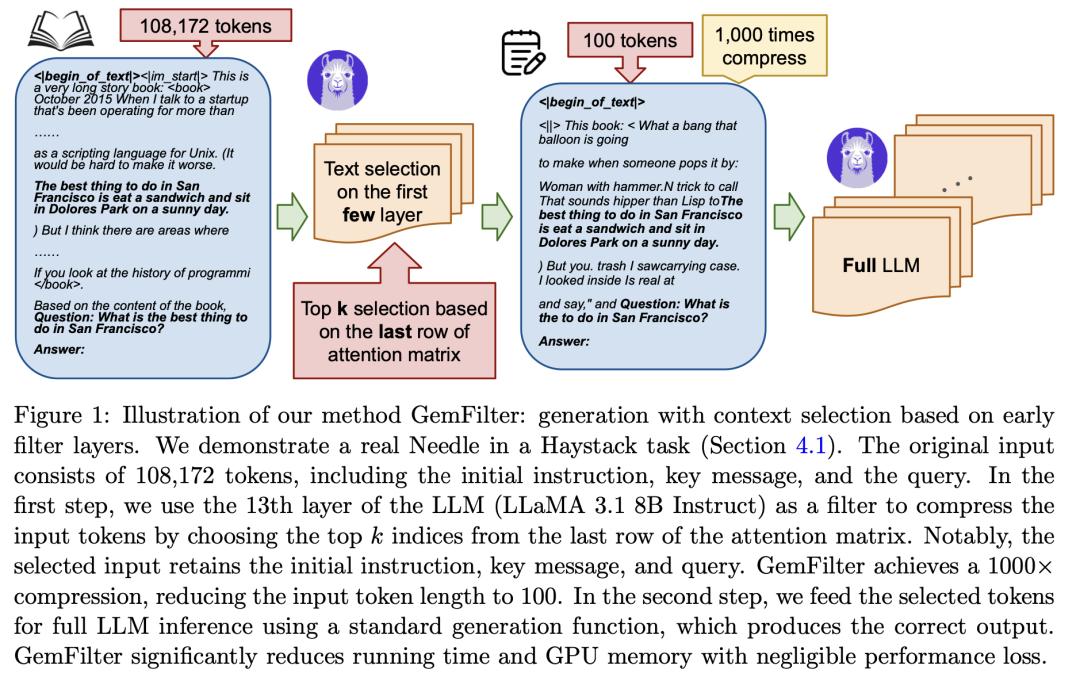
大语言模型(LLM)在处理长上下文输入方面表现出了非凡的能力,但这是以增加计算资源和延迟为代价的。来自威斯康星大学麦迪逊分校的研究团队及其合作者针对长上下文瓶颈提出了一种新方法,以加速 LLM 推断并减少 GPU 内存消耗。
研究表明,在生成查询答案之前,LLM 可以识别早期层中的相关 Token。利用这一发现,他们提出了一种算法,利用 LLM 的早期层作为过滤器来选择和压缩输入 Token,从而显著减少后续处理的上下文长度。
与标准注意力和 SnapKV/H2O 等现有技术相比,他们的 GemFilter 方法在速度和内存效率方面都有大幅提高。值得注意的是,与 SOTA 方法相比,它的速度提高了 2.4 倍,GPU 内存使用量减少了 30%。在 Needle in a Haystack 任务上进行的评估表明,GemFilter 的性能明显优于标准注意力和 SnapKV,在 LongBench 挑战赛上的表现也不相上下。GemFilter 操作简单,无需训练,可广泛应用于不同的 LLM。最重要的是,它允许人类检查所选的输入序列,从而提供了可解释性。
论文链接:
https://arxiv.org/abs/2409.17422
EMOVA:赋予语言模型看、听、说能力
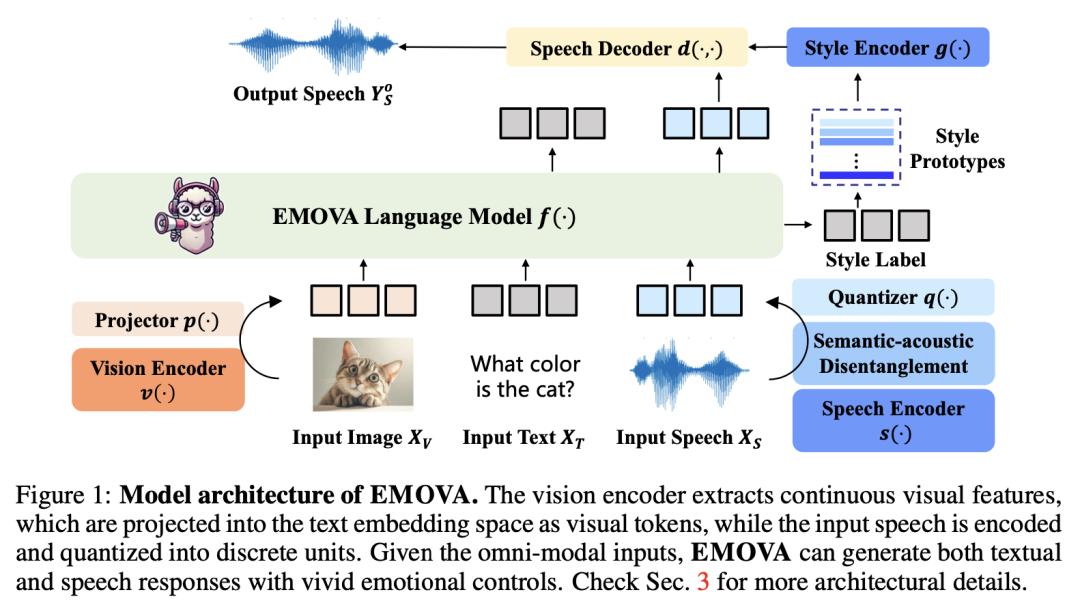
GPT-4o 是一种全模态模型,可实现具有不同情感和音调的语音对话,是全模态基础模型的里程碑。然而,在开源社区中,赋予大语言模型利用公开数据感知和生成端到端的图像、文本和语音的能力仍然是一项挑战。
现有的视觉语言模型依赖外部工具进行语音处理,而语音语言模型的视觉理解能力仍然有限,甚至没有视觉理解能力。为了弥补这一缺陷,来自香港科技大学、香港大学和诺亚方舟实验室的研究团队及其合作者推出了 EMOVA,使大语言模型具备端到端的语音能力,同时保持视觉语言的领先性能。
通过语义-声学分离的语音标记器,他们发现,与相应的双模态对齐的语音相比,全模态对齐能进一步增强视觉语言和语音能力。此外,他们还提出了一个轻量级风格模块,用于灵活控制语音风格(如情感和音调)。EMOVA 首次在视觉语言和语音基准测试中取得了 SOTA 性能,同时支持具有生动情感的全模态口语对话。
论文链接:
https://arxiv.org/abs/2409.18042
点击「阅读原文」,查看“2024必读大模型论文”素材来源官方媒体/网络新闻
原标题:《减少1000倍输入Token,新方法为长上下文LLM提速|大模型论文日报》
